Problem Statement
See the previous post. TL;DR: we want a mechanism that lets us link a test in one part of a codebase to other tests that rely on the assumption of that initial test, say that an API call response will include certain fields. If one team wants to make a change to that response, we want to make it clear what else might break if they make that change, and who they should probably talk with to build a shared understanding of what should be done next.
In the previous post we looked at doing this with def requirement and def relies_on methods: here we’re going to look instead at doing it with comment annotations, so:
# requirement anchor
# @REQUIREMENT: my_hounds includes key :breeding_stock
# relies_on anchor in same repo
# @RELIES_ON: my_hounds includes key :breeding_stock
# relies_on anchor in another repo
# @RELIES_ON: <repo:hounds_service>:my_hounds includes key :breeding_stock
Rewriting the Example
Let’s rewrite the example. lib/service.rb stays the same:
class Service
def my_hounds
{
breeding_stock: "Spartan",
traits: {
flewed_as: "Spartan",
sanded_as: "Spartan"
}
}
end
end
The spec/with_requirement_spec.rb changes its requirement and relies_on from methods to comment annotations, and already this lets us put them on individual examples and not just within example groups, giving us more flexibility:
require "service"
RSpec.describe "with requirement" do
subject { Service.new.my_hounds }
context "my_hounds" do
describe "keys in response" do
# @REQUIREMENT: my_hounds includes :breeding_stock
it "includes :breeding_stock" do
expect(subject).to include :breeding_stock
end
# @REQUIREMENT: my_hounds includes :traits
it "includes :traits" do
expect(subject).to include :traits
end
end
end
context "using my_hounds" do
describe "for one thing" do
# @RELIES_ON: my_hounds includes :breeding_stock
it "does something with :breeding_stock" do
expect(subject[:breeding_stock]).to eq("Spartan")
end
# @RELIES_ON: my_hounds includes :traits
it "does something with :traits" do
expect(subject[:traits][:flewed_as]).to eq("Spartan")
end
end
describe "for another thing" do
# @RELIES_ON: my_hounds includes :breeding_stock
it "checks something else" do
expect(subject[:breeding_stock]).not_to eq("Athenian")
end
end
end
end
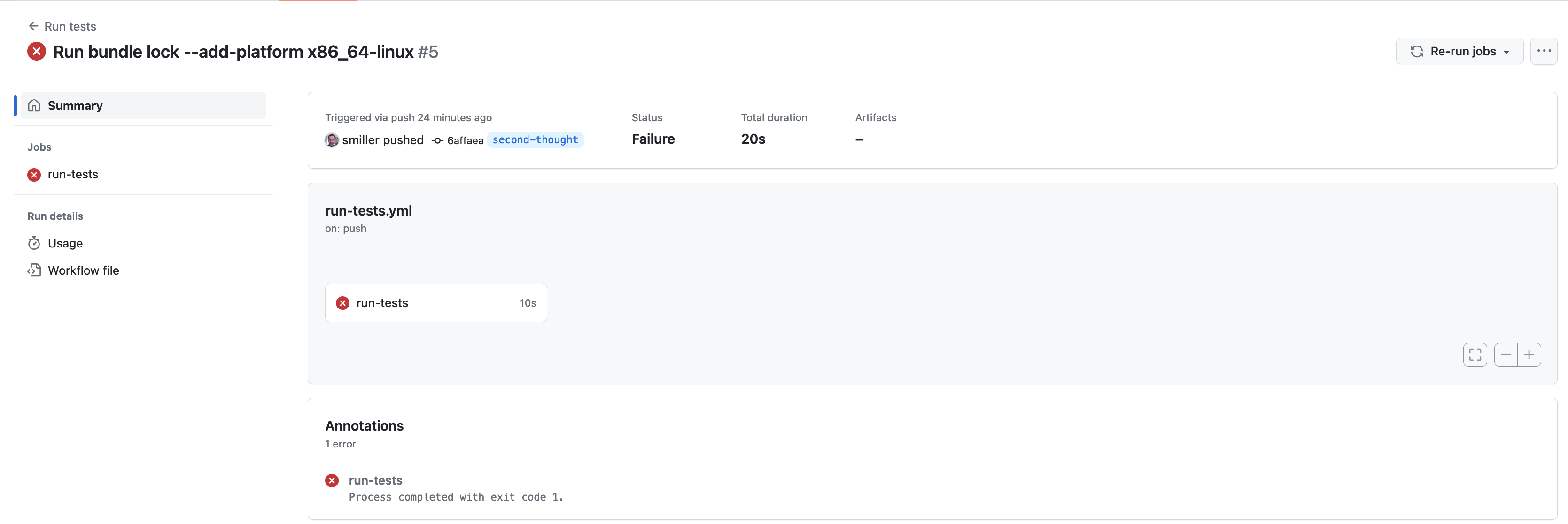
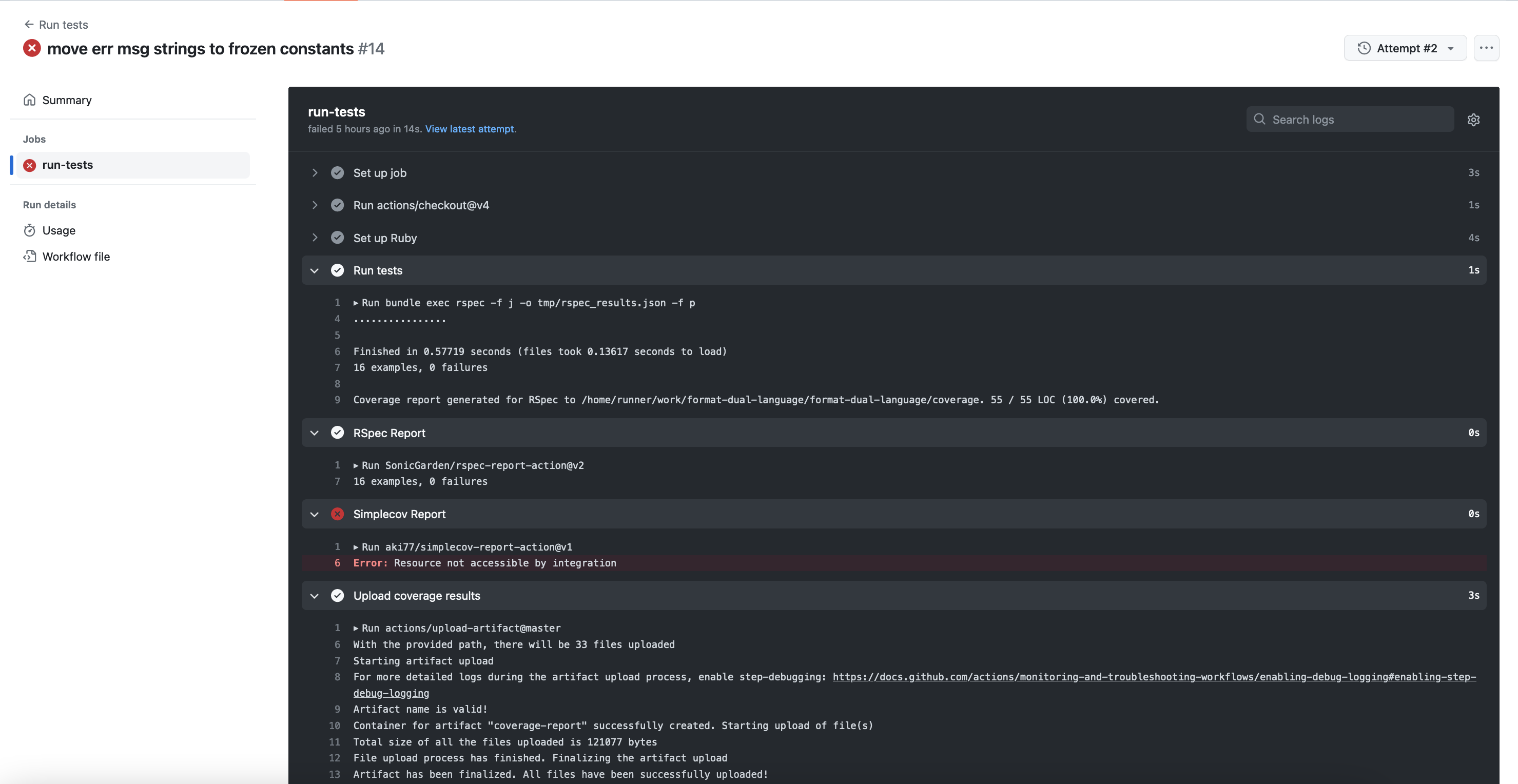
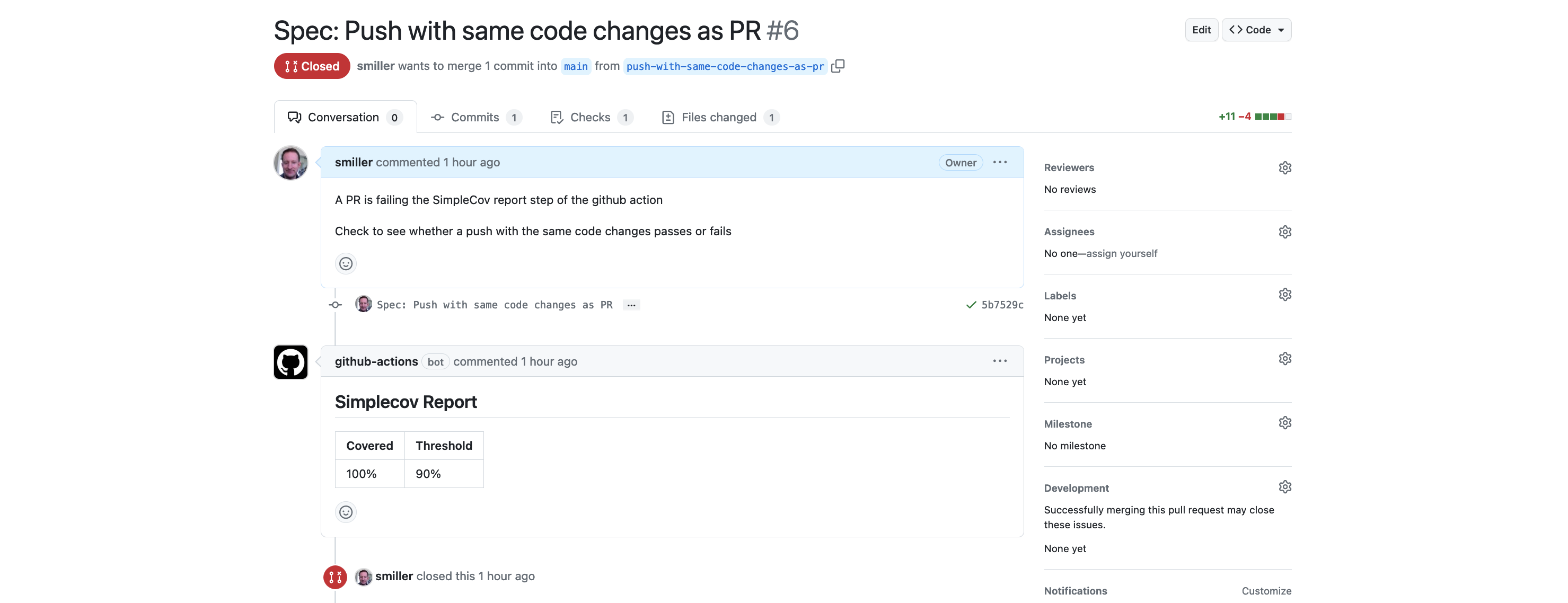
As before, this passes, and can be made to fail easily by commenting out line 5 of the lib/service.rb.
We can also create a related repo, with a spec referring back to the requirement in the first repo:
RSpec.describe "relies on related repo" do
describe "my_hounds from relies_on_example" do
# @RELIES_ON: <repo:relies_on_example_two>:my_hounds includes :breeding_stock
it "does something" do
expect(true).to be true
end
end
end
Building the Relies_on Lookup
It still makes sense to do this in the before(:suite), and to store the results in the added setting config.relies_on. So add in spec/spec_helper.rb, as before:
config.add_setting :relies_on
config.before(:suite) do
config.relies_on = reckon_relies_on
end
But instead of reading ObjectSpace, reckon_relies_on can start grepping instead. Running
def reckon_relies_on
stdout, _, _ = Open3.capture3("grep", "-nr", "# @RELIES_ON", "spec")
binding.pry
end
and looking at stdout gives us:
"spec/spec_helper.rb:110: stdout, _, _ = Open3.capture3(\"grep\", \"-nr\", \"# @RELIES_ON\", \".\")\n
spec/with_requirement_spec.rb:23: # @RELIES_ON: my_hounds includes :breeding_stock\n
spec/with_requirement_spec.rb:28: # @RELIES_ON: my_hounds includes :traits\n
spec/with_requirement_spec.rb:35: # @RELIES_ON: my_hounds includes :breeding_stock\n"
And by experimentation, and reusing / rewriting some of the grepping code from the last example, we can end up with:
def repos
[
# current repo
{
repo_url: "https://github.com/smiller/relies_on_example_two",
source_directory: "./",
relies_on_label: "# @RELIES_ON: "
},
# related repos
{
repo_url: "https://github.com/smiller/relies_on_example_two_related_repo",
source_directory: "./relies_on_example_two_related_repo/",
relies_on_label: "# @RELIES_ON: <repo:relies_on_example_two>:"
}
]
end
def reckon_relies_on
relies_on = Hash.new { |hash, key| hash[key] = [] }
FileUtils.rm_r("related_repos") if Dir.exist?("related_repos")
repo = repos[0]
relies_on = reckon_relies_on_for_one_repo(repo[:repo_url], repo[:source_directory], repo[:relies_on_label], relies_on)
FileUtils.mkdir("related_repos")
FileUtils.cd("related_repos")
repos[1..].each do |repo|
system("git clone #{repo[:repo_url]}")
relies_on = reckon_relies_on_for_one_repo(repo[:repo_url], repo[:source_directory], repo[:relies_on_label], relies_on)
end
relies_on
end
def reckon_relies_on_for_one_repo(repo_url, source_directory, relies_on_label, relies_on)
stdout, _, _ = Open3.capture3("grep", "-nr", relies_on_label, "#{source_directory}spec")
lines = stdout.split("\n")
lines.each do |line|
file, key = line.split(/\:\s+#{relies_on_label}/)
if file.include?("_spec.rb:")
matches = /#{source_directory}([\w\/\.]+):(\d+)/.match(file)
repo_link = "#{repo_url}/blob/main/#{matches[1]}#L#{matches[2]}"
relies_on[key] << repo_link
end
end
relies_on
end
After which, RSpec.configuration.relies_on is set to:
{"my_hounds includes :breeding_stock" =>
["https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L23",
"https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L35",
"https://github.com/smiller/relies_on_example_two_related_repo/blob/main/spec/relies_on_related_repo_spec.rb#L3"],
"my_hounds includes :traits" =>
["https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L28"]}
… which, checking against the github links, is what we expect it to be. So the relies_on lookup is now done.
Finding the Requirement
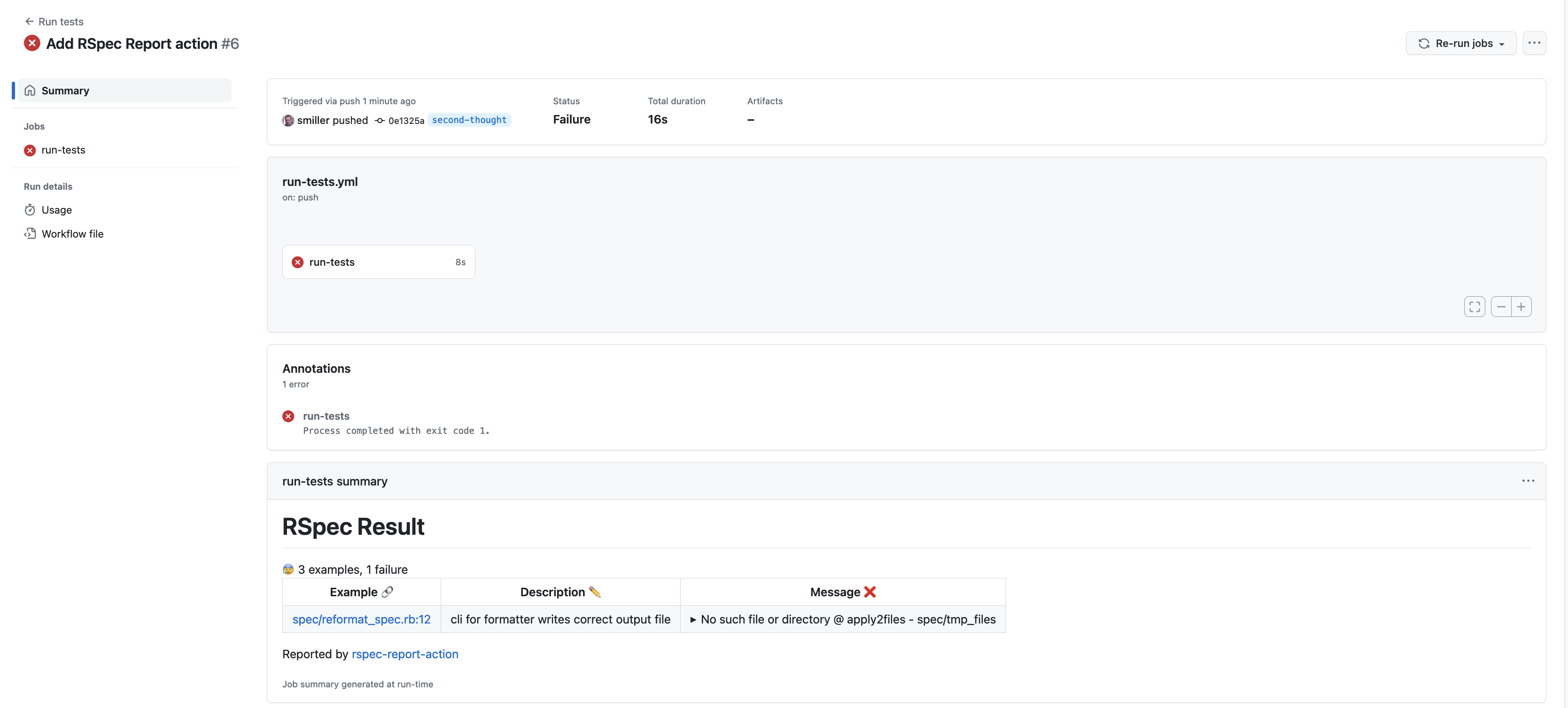
If we comment out line 5 of lib/service.rb to make the specs fail, we see that while it was simpler to build the relies_on lookup in this version, it’s going to be harder to get the requirement programmatically. When it was a method it was in scope so we could just call it to get the result, but now that it’s a comment annotation, we’ll have to work it out.
The simplest solution is a cheat with a manual step, but we’ll put it in to see the rest of the code work. We introduced a custom matcher in the previous post that takes the requirement as the argument. Let’s reintroduce it here, as spec/support/matchers.rb (also require 'support/matchers' in spec/spec_helper.rb so that it is accessible):
RSpec::Matchers.define :include_key do |key, requirement|
match { |hash| hash.include?(key) }
failure_message do
"expected #{actual.keys} to include key #{key}, but it didn't\n- #{actual}\n#{relies_on_message(requirement)}"
end
failure_message_when_negated do
"expected #{actual.keys} not to include key #{key}, but it did\n- #{actual}\n#{relies_on_message(requirement)}"
end
end
Since that uses the relies_on_message(requirement) method, let’s add that back into spec/spec_helper.rb too:
def relies_on_message(requirement)
relies_on = RSpec.configuration.relies_on.fetch(requirement, [])
if relies_on.any?
"\nOther specs relying on this: \n- #{relies_on.join("\n- ")}"
else
""
end
end
Now, since we’re explicitly (and only) calling the new include_key matcher when we know we’ve got a requirement, and since we can see from the annotation above the method what the requirement is:
# @REQUIREMENT: my_hounds includes :breeding_stock
it "includes :breeding_stock" do
expect(subject).to include :breeding_stock
end
we could change line 11 of with_requirement_spec.rb from
expect(subject).to include :breeding_stock
to
expect(subject).to include_key(:breeding_stock, "my_hounds includes :breeding_stock")
copying the requirement from line 9. This is a manual step and a duplication and we’d very much prefer to get rid of it, but if we try that now and run the specs, we do get the expected error message with related github links:
1) with requirement my_hounds keys in response includes :breeding_stock
Failure/Error: expect(subject).to include_key(:breeding_stock, "my_hounds includes :breeding_stock")
expected [:traits] to include key breeding_stock, but it didn't
- {:traits=>{:flewed_as=>"Spartan", :sanded_as=>"Spartan"}}
Other specs relying on this:
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L23"
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L35"
- "https://github.com/smiller/relies_on_example_two_related_repo/blob/main/spec/relies_on_related_repo_spec.rb#L3"
# ./spec/with_requirement_spec.rb:11:in `block (4 levels) in <top (required)>'
(The quotation marks aren’t in the actual output: I’ve added them in because without them WordPress leaves off the line number suffix (e.g. #L23) from the link, so it just goes to the file, but with them it includes the line number suffix, so if you click on the links above within their quotation marks they go to the file and line number.)
Changes from this section are here.
Finding the Requirement without Cheating
It was good to see everything working, but it feels wrong to be manually copying a string when it’s two lines away. Can we do better? Let’s see.
If put back our binding.pry and inspect the example, we see it gives us the file and the line number where the example begins:
self.inspect
=> "#<RSpec::ExampleGroups::WithRequirement::MyHounds::KeysInResponse \"includes :breeding_stock\" (./spec/with_requirement_spec.rb:10)>"
We can regexp to get out the file and line number from that:
matches = /.+\((.+):(\d+)\).+/.match(self.inspect)
=> #<MatchData
"#<RSpec::ExampleGroups::WithRequirement::MyHounds::KeysInResponse \"includes :breeding_stock\" (./spec/with_requirement_spec.rb:10)>"
1:"./spec/with_requirement_spec.rb"
2:"10">
This feels potentially fragile and accidental, but let’s run with it for now. Now that we’ve got the file, we can check for # @REQUIREMENT: comments within it:
stdout, _, _ = Open3.capture3("grep", "-nr", "# @REQUIREMENT: ", matches[1])
stdout
=> "./spec/with_requirement_spec.rb:9: # @REQUIREMENT: my_hounds includes :breeding_stock\n./spec/with_requirement_spec.rb:15: # @REQUIREMENT: my_hounds includes :traits\n"
And if the requirement is at the example level, we know its line_number will be matches[2].to_i - 1 => 9, so we can iterate over the requirement lines looking for that:
lines = stdout.split("\n")
lines.each do |line|
line_matches = /#{example_matches[1]}:(\d+).+# @REQUIREMENT: (.+)/.match(line)
if line_matches[1].to_i == line_number
puts "REQUIREMENT IS: #{line_matches[2]}"
end
end
So we can create a reckon_requirement(example) method in spec/spec_helper.rb:
def reckon_requirement(example)
example_matches = /.+\((.+):(\d+)\).+/.match(example.inspect)
line_number = example_matches[2].to_i - 1
stdout, _, _ = Open3.capture3("grep", "-nr", "# @REQUIREMENT: ", example_matches[1])
lines = stdout.split("\n")
lines.each do |line|
line_matches = /#{example_matches[1]}:(\d+).+# @REQUIREMENT: (.+)/.match(line)
if line_matches[1].to_i == line_number
return line_matches[2]
end
end
end
And call it instead where we’re passing in the manually-typed requirement in line 11 of with_requirement_spec.rb:
expect(subject).to include_key(:breeding_stock, reckon_requirement(self))
Then, in this case, because the comment annotation is on the specific example, it works, and we get the expected “Other specs relying on this: …” error message without manually copying the requirement:
1) with requirement my_hounds keys in response includes :breeding_stock
Failure/Error: expect(subject).to include_key(:breeding_stock, reckon_requirement(self))
expected [:traits] to include key breeding_stock, but it didn't
- {:traits=>{:flewed_as=>"Spartan", :sanded_as=>"Spartan"}}
Other specs relying on this:
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L23"
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L35"
- "https://github.com/smiller/relies_on_example_two_related_repo/blob/main/spec/relies_on_related_repo_spec.rb#L3"
# ./spec/with_requirement_spec.rb:11:in `block (4 levels) in <top (required)>'
This does depend on the assumption that the requirement comment annotation will be at the example level, not on an example group level, which is not a restriction we had with the previous solution. But it’s probably a reasonable assumption. And if it ever isn’t, we can either dig deeper into a more complex automated solution or pass in a manually-copied string.
(But if we do find ourselves needing to pass in manually-copied strings, we should at least write a spec that gathers all the requirements from the comment annotations and all of the explicit requirement strings passed into custom matchers and verify that all the custom strings are valid requirements from the list of comment annotations.)
But if we’re good with the restriction that requirement comment annotation is at the specific example level, this now works automatically. Changes from this section are here.
Next-Day Improvement
Having just watched Noel Rappin’s RailsConf 2023 talk, I was reminded that Ruby gives us __FILE__ and __LINE__ to read the current file name and line number, which feels better and more direct than using a regexp as we did above.
Since reckon_requirement only needs the file name and line number, let’s change it from reckon_requirement(example) to reckon_requirement(file_name, line_number). In fact, we can pass in the line number of the requirement (in our case, __LINE__ - 2, but this also gives us the flexibility to reference a requirement on an example group and not just use the one on the example, which we didn’t have before), and, in case we make a mistake counting line numbers, let’s raise an error in reckon_requirement if it doesn’t find a requirement at the specified line number.
We change the call in the spec from:
# @REQUIREMENT: my_hounds includes :breeding_stock
it "includes :breeding_stock" do
expect(subject).to include_key(:breeding_stock, reckon_requirement(self))
end
to
# @REQUIREMENT: my_hounds includes :breeding_stock
it "includes :breeding_stock" do
expect(subject).to include_key(:breeding_stock, reckon_requirement(__FILE__, __LINE__ - 2))
# __LINE__ is 11, and the requirement is on line 9, hence __LINE__ - 2
end
and we change reckon_requirement in spec_helper.rb to:
def reckon_requirement(full_path_file_name, line_number)
file_name = "./#{full_path_file_name[`pwd`.length..]}"
stdout, _, _ = Open3.capture3("grep", "-nr", "# @REQUIREMENT: ", file_name)
lines = stdout.split("\n")
lines.each do |line|
matches = /#{file_name}:(\d+).+# @REQUIREMENT: (.+)/.match(line)
if matches[1].to_i == line_number
return matches[2]
end
end
raise "requirement expected but not found at file #{file_name} line #{line_number}"
end
We can change the line_number we pass in at line 11 to __LINE__ - 3 (line 8, the line above the requirement) to verify we get the error with a usefully specific message:
Failures:
1) with requirement my_hounds keys in response includes :breeding_stock
Failure/Error: raise "requirement expected but not found at file #{file_name} line #{line_number}"
RuntimeError:
requirement expected but not found at file ./spec/with_requirement_spec.rb line 8
# ./spec/spec_helper.rb:177:in `reckon_requirement'
# ./spec/with_requirement_spec.rb:11:in `block (4 levels) in <top (required)>'
From requirement expected but not found at file ./spec/with_requirement_spec.rb line 8 we can look back at our spec file
describe "keys in response" do
# @REQUIREMENT: my_hounds includes :breeding_stock
it "includes :breeding_stock" do
expect(subject).to include_key(:breeding_stock, reckon_requirement(__FILE__, __LINE__ - 2))
end
and see we meant line 9 / __LINE__ - 2 (not line 8 / __LINE - 3), and fix it easily.
Having fixed that, we can also comment out the line in lib/service.rb and verify that we still get the error message including the other specs relying on this block.
Looking at that block:
Other specs relying on this:
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L23"
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L35"
- "https://github.com/smiller/relies_on_example_two_related_repo/blob/main/spec/relies_on_related_repo_spec.rb#L3"
It occurs that naming the requirement instead of just saying “this” would probably be more useful, so we change relies_on_message(requirement) to say
"\nOther specs relying on requirement '#{requirement}': \n- #{relies_on.join("\n- ")}"
And re-run to get a more informative error:
Other specs relying on requirement 'my_hounds includes :breeding_stock':
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L23"
- "https://github.com/smiller/relies_on_example_two/blob/main/spec/with_requirement_spec.rb#L35"
- "https://github.com/smiller/relies_on_example_two_related_repo/blob/main/spec/relies_on_related_repo_spec.rb#L3"
That feels better. Changes from this section are here.
Initial Conclusion
I think I prefer this solution to the one from the previous post, largely because of the github-to-specific-line-number links in all cases. It is true that we’re encoding data in comments, which can be risky, but since they’re clearly structured comments – # @REQUIREMENT: and # @RELIES_ON: – they feel more secure.
Also, since we’ve now got worked examples of both, we can let them breathe side-by-side for a bit, try them out on other examples, possibly / probably discover different edge cases, and come to a better-founded conclusion. It’s a lot easier to reason about now that both exist as running code.